C Code Topics
Last updated 16 October 2012
Introduction
C is not a big language, but it is very powerful and wears well as one's experience with it grows (Kernighan and Ritchie).
Broadly speaking I have 2 goals in mind:
- Clarify some C concepts in plain english, highlighting some of its pitfalls.
- Archive some (what I believe to be) useful code.
I hope to bring something new to the vast barrage of information on C and will also assume that the reader already has a basic understanding of the language. Like many other texts on this site, it will be a work in progress.
The official bible on C is the book The C Programming Language by the creators of C, Brian W. Kernighan and Dennis M. Ritchie (ISBN 0-13-110362-8). It's a surprisingly small book with its 260 pages (190 if you don't count the reference section), but needs to be read slowly as it is very dense. It also assumes you have a general understanding of how memory works.
Another very useful book is The C Puzzle book by Alan R. Feuer (ISBN 0-201-60461-2). It presents the reader with a series of challenges that are designed to bring to the fore some pitfalls the C programmer may (and eventually will) encounter.
Of course there's ample stuff on the net - one of the best series is the Programming Paradigms course by Jerry Cain at Stanford University. All the material can be downloaded from the Stanford University Computer Science Department website. Like mathematics, C can only be mastered by actually using it - as each example reveals slightly different aspects of the language.
For all practical purposes, it can be said that electronics gave birth to programming. It is a language that evolved out of a need to set bits in registers and handle communication between components. Originally, only machine or assembly language was used - but C gradually evolved out of a need to make the language more transportable (using different processors) and readable. Much can be learned from electronics engineers who generally deal with embedded systems, and don't have the luxury of operating systems that take care of interrupts and the likes. Amongst many things, they make heavy use of macros, bit operations, pointer manipulation, function pointers, and the dreaded state machines - which come natural to them because state machines really reflect the internal states of the electronics. They also work towards greater efficiency in order to handle the immensely fast clock cycles and minimal available RAM and the resulting small stack size. In other words, it pays to have a basic understanding of how these electronic components interact.
Memory representation
It helps to look at memory from 3 different perspectives:
- The Code where you declare the variable
- The Compiler which maintains the symbol table
- The Memory Location
Following tables show the state of affairs after an int i is initialised to 0. Memory has been set aside, and the value 0 is present in memory:
Code
int i = 0;
Symbol Table
|
i |
0x1234 |
|
|
|
|
|
|
Memory
|
|
... |
|
0x1234 |
0 |
|
|
... |
0x1234 is an address (location in memory) given in hexadecimal notation. The symbol table keeps track of where variables and objects reside in memory. Components appear in memory from the bottom upwards, however the way that bytes are grouped depends on the processor: Windows machines use the Little Endian mechanism (least significant bytes first).
In reality, memory consists of several areas, most boundaries between these areas are fixed, but the boundary between the heap and the stack is variable. The following illustration lists the types that are typically stored in these areas:
|
0x00000000 |
text |
|
|
|
data |
|
|
|
bss block starting symbol |
|
|
|
heap |
|
|
|
⇑ ⇓ |
|
|
0xFFFFFFFF |
stack |
|
Following example illustrates which areas of memory are being used:
int size; // allocated in **bss.** set to 0 at startup
// available until program termination
char *f(void)
{
char *p; // allocated on **stack** at start of function f
// de-allocated by return from function f
size = 8; // allocated in **data** - initialises at compile time
p = malloc(size); // allocated 8 bytes in **heap** by malloc()
// de-allocated by calling free(p)
return p;
}
Pointer confusion
The key advantage of pointers (in any language) is that two or more entities can cooperatively share and manipulate a single memory structure. In Java, complex types such as arrays and objects are automatically implemented using pointers. They are hidden from the programmer - thus making it impossible to access wrong areas of memory. This is Java's intention since it makes the language more secure.
Indeed, using pointers enables the programmer to access memory at any point at any time and manipulate its data. C doesn't have the intelligence to handle wrong access even if it wanted to. This naturally brings its own risks, suffice to say that a clear understanding of pointers is crucial to learning the C language.
The concept of pointers in C, while giving the programmer much power, is also a source of great confusion. To my mind there are 2 main reasons for this confusion:
- The different meaning of the asterisk in declaration and dereferencing
When declaring a pointer p, the asterisk is used to indicate that we are declaring a pointer to a type. Thus a character pointer is declared as char *p. However, when we want to know what value p is pointing to, we also use *p, saying we are dereferencing it. So in this sense the asterisk functions as an operator. Both uses of the asterisk are very different. - The difference between array names and pointer names
When we have an array a[], then PRINT(a) prints the address of the first element this array resides at, so in this case a is synonymous with &a. However if we have a pointer p pointing to this array, PRINT(p) will not print the address were the pointer resides at but the value of the address stored at p.
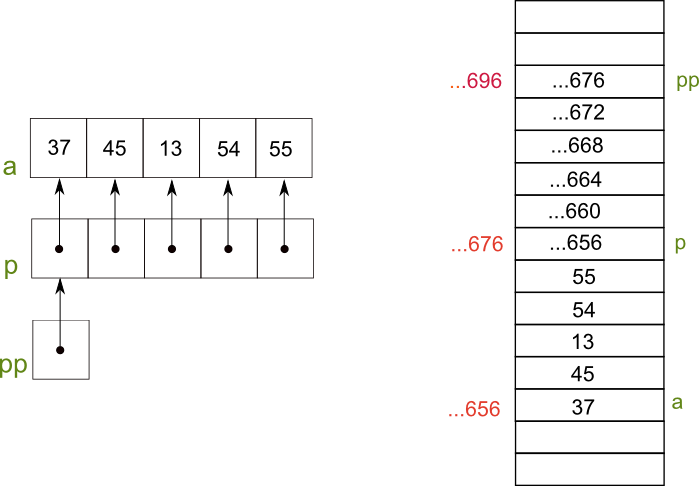
Here's an example to illustrate that last point. Consider an int array with some values, an int pointer array each element of which points to the corresponding element in the int array, and a pointer to this int pointer array:
int a[] = {37, 45, 13, 54, 55};
int *p[] = {a, a+1, a+2, a+3, a+4};
int **pp = p;
Assuming a macro, PRINT(), that prints out the values in decimal, try to figure what the following code would print:
PRINT(a, *a); PRINT(p, *p, **p); PRINT(pp, *pp, **pp);
ANSWER: The first line would first print the address of a, followed with the value of the first element at a, which is 37.
The second line prints the address of p, followed with the address of a, followed with the value 37.
Line 3 prints exactly the same as line 2, thus (as they say) illustrating the point.
Following diagram shows the above situation. The red numbers are the memory addresses in decimal, only the last digits are shown for clarity. Which addresses are being used depends on what else is going on with your computer. All we know is that it will reside within a certain range. Note that addresses increment in 4 byte chunks.
To summarize, comparing the 3 basic constructs:
int a
- Print(&a) prints the address of the location
- Print(a) prints the int value residing at this address
int a[]
- Print(a) AND Print(&a) prints the address of the first element of the array
- Print(*a) prints the value that resides at this first element's address
int *p
- Print(&p) prints the address of the pointer.
- Print(p) prints the value of p which is an address to another location.
- Print(*p) prints the value that resides at the location it is pointing to.
Pointer Arithmetic
Some interesting pointer arithmetic can be shown using the example above. Assume you increase the pointer pp:
pp++;
What will the print results be in the following cases:
PRINT(pp - p); PRINT(*PP - a); PRINT(**pp);
ANSWERS:
First line: Incrementing pp
results in it now pointing to p[1]
which resides at location ...680, while p
still resides at ...676.
Both elements in pp - p are addresses,
and consequently use pointer arithmetic
, meaning statements are evaluated in chunks of
sizeof(type). Since we are working with 32 bit integers, the size is 4 bytes. Therefore pp - p =
680 - 676 = 4 bytes = 1. Hence the result will be 1.
Second line: *pp dereferences
what resides at p[1] which is the
address of a[1], i.e. ...660. The second
term a is synonymous with
&a[0], the address of the first element
of a which is ...656. The
result again uses pointer arithmetic: 660 - 656 = 4 bytes = 1.
Third line: We saw that *pp evaluated to
the address of a[1], i.e. ...660. Dereferencing
this address gives you the value that resides at this address, which is 45.
Compact code writing
Sometimes writing code in a compact form can help the clarity. Take for example the following line:
y = MAX(j,k) / x != 0 ? x : NEARZERO);
This line puts the emphasis on the fact that assignment to y is the primary idea, subordinating both tests. To construct this line you need to know the precedence and associativity of operations. They are listed in The C Programming Book on page 53. The != operator takes precedence over the /. It first ensures that a zero value of x is replaced with another low value after which the division can be safely executed.
Following code replaces tabs by spaces:
for(i=0; (c=getchar())!=EOF && c!='\n'; i++){
s[i] = c != '\t' ? : ' ';
}
The first line illustrates how the for loop condition need not be related to i. The loop
will simply continue until it is false (in this case until the end of the file or a new line is reached).
The second line is similar to the first example. If char c is not a tab, it will remain c, but if it is a tab, it
will be replaced by a space.
Following example prints n elements of an array, 10 per line, with each column separated by one blank, and each line terminated with a new line:
for(i=0; i <: n; i++){
printf("%6d%c", a[i], (i%10==9 || i==n-1) ? '\n' : ' ');
}
Again, it is necesarry to know the precedence and associativity table on page 53 of
the same book. The order of precedence of the operations in the last parameter of the printf function is:
-
%
==
||
:
?
With this knowledge we can rewrite the line in the last parameter:
(((((i%10)==9) || (i==(n-1))) ? '\n') : ' ')
This line, while clear in its intentions becomes a little harder to read, but it avoids ambiguity. As a compromise I believe the following line most legible, it assumes you know at least some basic precedences (such as precedence of arithmetic operations over logical ones) and uses spaces to further indicate this, e.g. the modulus operator is grouped with the number 10 to indicate it needs to be executed before comparing it with number 9.
(((i%10 == 9) || (i == n-1)) ? '\n' : ' ')
In some situations, the order in which the operands of an operator are evaluated depends on the compiler. A simple line like ...
a[i] = i++;
... will be interpreted differently depending on the compiler. The value of the subscript i is ambiguous in that it can be either the old i or the newly incremented one.
Bit operations
Though heavily used by the electronics mob, bit operations are rarely used by higher level programmers, hence this section is geared towards the latter.
When working with bits it is necessary to be able to convert hexadecimal to binary. This is much easier than converting binary to decimal since both binary and hexadecimal are powers of 2. All one needs to remember is that one hexadecimal digit represents 4 bits. So for example, 0x40A7 can be written in binary as 0100 0000 1010 0111, which are the actual binary representations of the numbers 4, 0, 10 and 7. A Hexadecimal number is preceded with 0x.
The & operator
Bit operations are another example that underlines the language of electronics. They are especially used to turn register bits off and on. They are rarely used in higher lever programming, but are nevertheless an important aspect of the C language. The first bit operator is the & operator which is used to mask off bits:
char x = 0x9A; char mask = 0x01; x &= mask; // result x: 1001 1010 mask: 0000 0001 &: 0000 0000 // Mod 4 operation: char x = 0x9A; char mask = 0x03; x &= mask; // result x: 1001 1010 mask: 0000 0011 &: 0000 0010
The hexadecimal values 0x1 and 0x3 in the above examples are referred to as masks. A value of 1 in the mask is like a window that reveals the value of x at that location. Alternatively wherever there is a 0, the value is 0.
Another example which uses masks and does some bit shifting is used in Windows Programming. In Windows, a WORD is a 2 byte value while a DWORD is a 4 byte value. The following macro takes the upper 2 bytes from a DWORD:
Define HIWORD(l) (WORD)(((DWORD)(l) >> 16) & 0xFFF)); // result example DWORD: 0011 1101 1011 1011 1000 1111 1010 1010 >>16: 0000 0000 0000 0000 0011 1101 1011 1011 0xFFF: 0000 0000 0000 0000 1111 1111 1111 1111 & (WORD) 0011 1101 1011 1011
The implementation of LOWORD is much simpler as all it needs to do is cast the DWORD to a WORD and only the lowest 2 bytes will show.
The bit shifting is self-explanatory, it simply shifts the bits in the indicated direction, filling the vacated bits with zeros.
Another example combines the & operation with the condensed if else clause. This line of code is part of a Windows program which uses a TextMetric struct's Pitch and Family field's last bit to determine whether this font has variable (1) or fixed pitch (0) and adjusts the capital font's width accordingly:
CxCaps = (tm.tmPf & 1 ? 3 : 2) * cxChar / 2; // last digit for tnPf is 1 for variable size, 0 for fixed size
The | operator
The second bit operator is the | operator. It is used to switch on some bits:
short x = 0x0400; short pattern = 0x0200; // switch on pattern x |= pattern; // result 0x0400: 0000 0100 0000 0000 0x0200: 0000 0010 0000 0000 |=: 0000 0110 0000 0000
The 1's in the 0x0200 pattern will switch on the respective bits in x (if it is not already zero).
Following table outlines the 3 basic bit operations
|
&= |
1001 0101 |
register |
|
|
0011 0001 |
applied mask |
<-- '0's clear bits in register |
|
|
|
0001 0001 |
register |
|
|
|
|
|
|
|
|= |
1001 0101 |
register |
|
|
0011 0001 |
applied mask |
<-- '1's set bits in register |
|
|
|
1011 0101 |
register |
|
|
|
|
|
|
|
^= |
1001 0101 |
register |
|
|
0011 0001 |
applied mask |
<-- '1's toggle bits in register |
|
|
|
1010 0100 |
register |
|
Preprocessor Statements
The following included file is useful for printing the results of code examples:
#include <stdio.h>
#define PR(fmt,val) printf(#val " = %" #fmt "\t", (val))
#define NL putchar('\n')
#define PRINT1(f,x1) PR(f,x1), NL
#define PRINT2(f,x1,x2) PR(f,x1), PRINT1(f,x2)
#define PRINT3(f,x1,x2,x3) PR(f,x1), PRINT2(f,x2,x3)
#define PRINT4(f,x1,x2,x3,x4) PR(f,x1), PRINT3(f,x2,x3,x4)
The Ring Buffer or Circular Queue
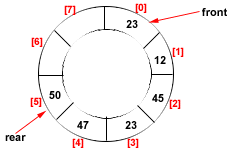
A circular queue, also called ring buffer or circular array is widely used by embedded C programmers because of its efficiency and also because insertion and deletion are totally independent, which means that you don't have to worry about an interrupt handler trying to do an insertion at the same time your main code is doing a deletion.
Algorithm for Insertion:
- If rear of the queue is pointing to the last position then go to step-2 or else step-3
- make the rear value as 0
- increment the rear value by one
- if the front points where rear is pointing and the queue holds a not NULL value for it, then its a queue overflow state, so quit; else go to step-5
- insert the new value for the queue position pointed by the rear
Algorithm for deletion:
- If the queue is empty then say empty queue and quit; else continue
- Delete the front element
- If the front is pointing to the last position of the queue then step-4 else step-5
- Make the front point to the first position in the queue and quit
- Increment the front position by one
Since embedded systems demand the least amount of overhead, the array is used as a buffer rather than a linked list in the following example:
#include <stdio.h>
#define MAX 5
struct queue
{
int arr[MAX];
int rear,front;
};
int isempty(struct queue *p)
{
if(p->front ==p->rear)
return 1;
else
return 0;
}
void insertq(struct queue *p,int v)
{
int t;
t = (p->rear+1)%MAX;
if(t == p->front)
printf("\nQueue Overflow\n");
else
{
p->rear=t;
p->arr[p->rear]=v;
}
}
int removeq(struct queue *p)
{
if(isempty(p))
{
printf("\nQueue Underflow");
exit(0);
}
else
{
p->front=(p->front + 1)%MAX;
return(p->arr[p->front]);
}
}
int main(void)
{
struct queue q;
char ch;
int no;
q.rear=q.front =0;
insertq(&q,7);
insertq(&q,10);
printf("\n%d\n",removeq(&q));
printf("%d\n",removeq(&q));
removeq(&q);
getch();
return 0;
}